- Published on
The Road to GraphQL At Enterprise Scale

Table of contents
- Intro
- Backstory
- I. Introduce GraphQL Federation as API Gateway
- II. Decompose monolith service to GraphQL Subgraphs (Microservices)
- III. Mesh and/or add support to existing services
- IV. Schema Registry
- V. Observability
- Closing Thoughts
Intro
GraphQL was designed to allow your API to evolve continuously in response to new product requirements without the burden of versioning, simplify the process of getting data from different sources and support typings for API out of the box.
Our team is responsible for developing an API — a single endpoint that provides all the necessary data to render the UI for clients and core web infrastructure for the customer portal. Several years ago, we initially used REST endpoints to gather data from multiple services. However, over time, the number of these API calls has grown, and it has become increasingly difficult to manage this system swiftly and maintain up-to-date synchronization between teams.
We started looking for a solution that would help us easily support the development of the portal and the ability to migrate the current monolith to microservices. The experience of big tech companies (e.g. Shopify, PayPal, Atlassian, Airbnb, GitHub, Twitter, and so on) with successful usage of GraphQL for their core products that have High Load & High Availability at the same time was a vital sign for introducing GraphQL in our scope.
In this article, I focus on integrating GraphQL within an enterprise as an infrastructure without considering load balancing, external infrastructure, cache configurations and other important things not directly related to our migration from perspective of GraphQL.
Backstory
The situation when you can introduce GraphQL as a core service for an enterprise from the scratch is a dream because you usually have existing infrastructure, and you need to integrate it into the existing codebase as smoothly as possible.
Our case is not an exception. We had an infrastructure for the customer portal based on multiple REST calls from dozens of UI applications and BFFs to thousands of microservices. In that case, you have the possibility to simplify the work through libraries that contains some needed typings, the logic around HTTP clients, shared configuration, etc. Services could be written with different protocols, e.g., SOAP, RPC, REST... Most of the services exposes through REST for NodeJS and it expects different HTTP headers.
We already used libraries and shared configurations for our NodeJS services and UI-related applications (React, Vue, Angular, or pure HTML) for these purposes. But whenever you need to update something in that library or within shared configuration, it takes a lot of work because you should patch every service & application and spend many hours with product teams and infrastructure teams.
The goal was to implement such a system that can be maintained by one team and has everything from the data perspective for portal purposes. In the meantime, product teams don't need to go deeply into details to realize how to call new services, which headers they should provide, and how to see API (Swagger, Postman, etc.).
GraphQL had the perfect fit for that purpose and contained many additional benefits for us:
- Single typed endpoint for different clients (Web, Mobile, BFF, internal services written on Kotlin, Java, .NET, etc.).
- Playground with the described schema that is a super helpful feature fo quick testing new features (e.g. GraphiQL.
- The unified way of exposing data through a single endpoint.
- Language agnostic.
As a team, we are responsible for maintaining the entire portal. The excellent direction is a simplification of the process of how clients can get all the needed data. We had a monolith service for the whole portal that combines all needed logic: auth, data about users, features, meta information, analytics, and so on. A simplified diagram without extra infrastructure (load balancing, caching, etc.) might look like this:
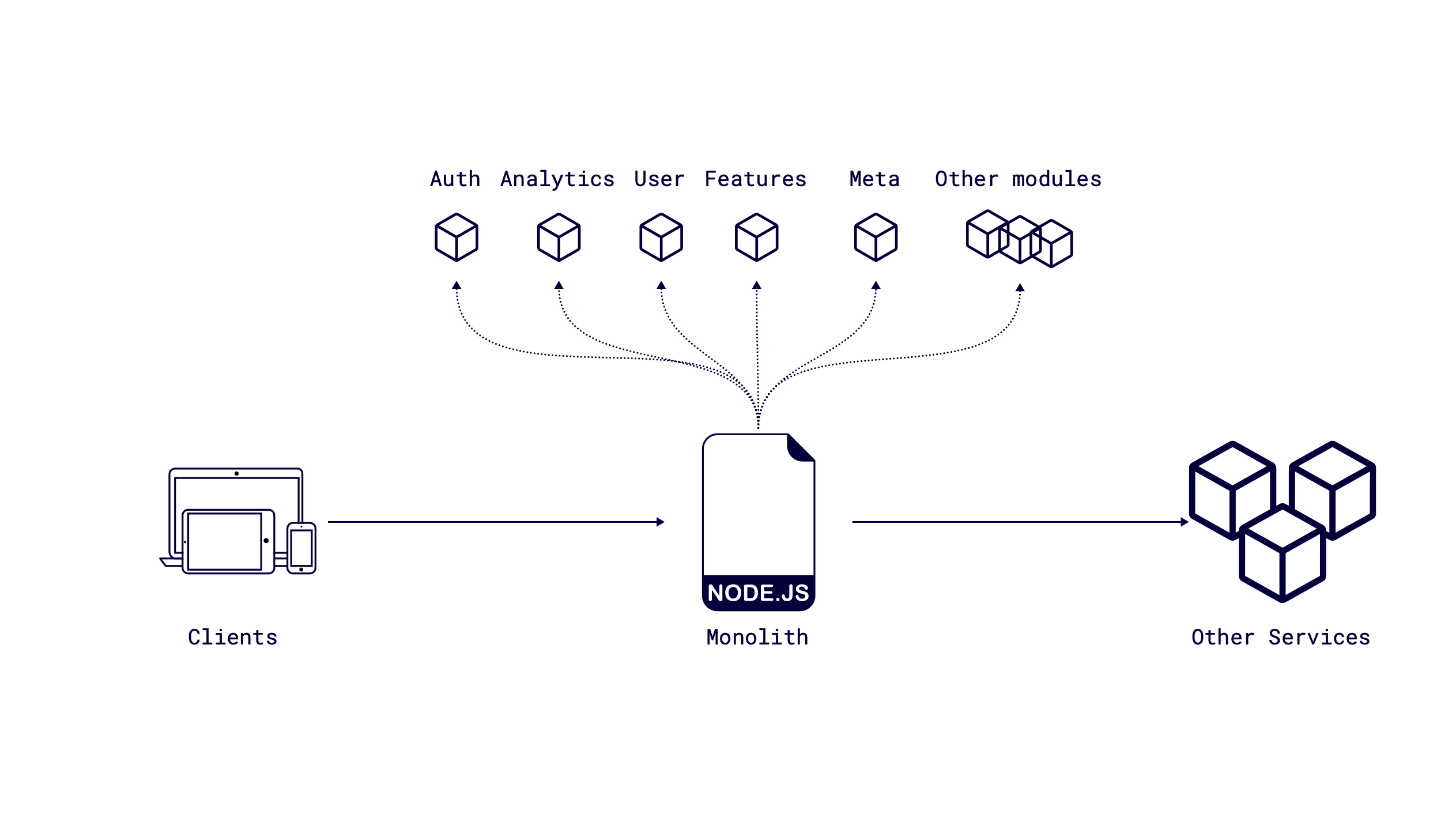
The problem with this approach is the amount of redeploys and the possibility of breaking some core functionality when upgrading product-related modules. As a team, we looked very carefully at each PR, as product teams could change functions, interfaces, and general code used in different modules in the monolith, and it was essential to keep track of every change in each PR. The number of such PRs could be in the dozens per day, which meant that our team had spent much time manually reviewing and revising. And... As you know, this is a place for mistakes.
I. Introduce GraphQL Federation as API Gateway
First of all, you need add layer for future microservices architecture as a gateway which processes incoming requests to GraphQL.
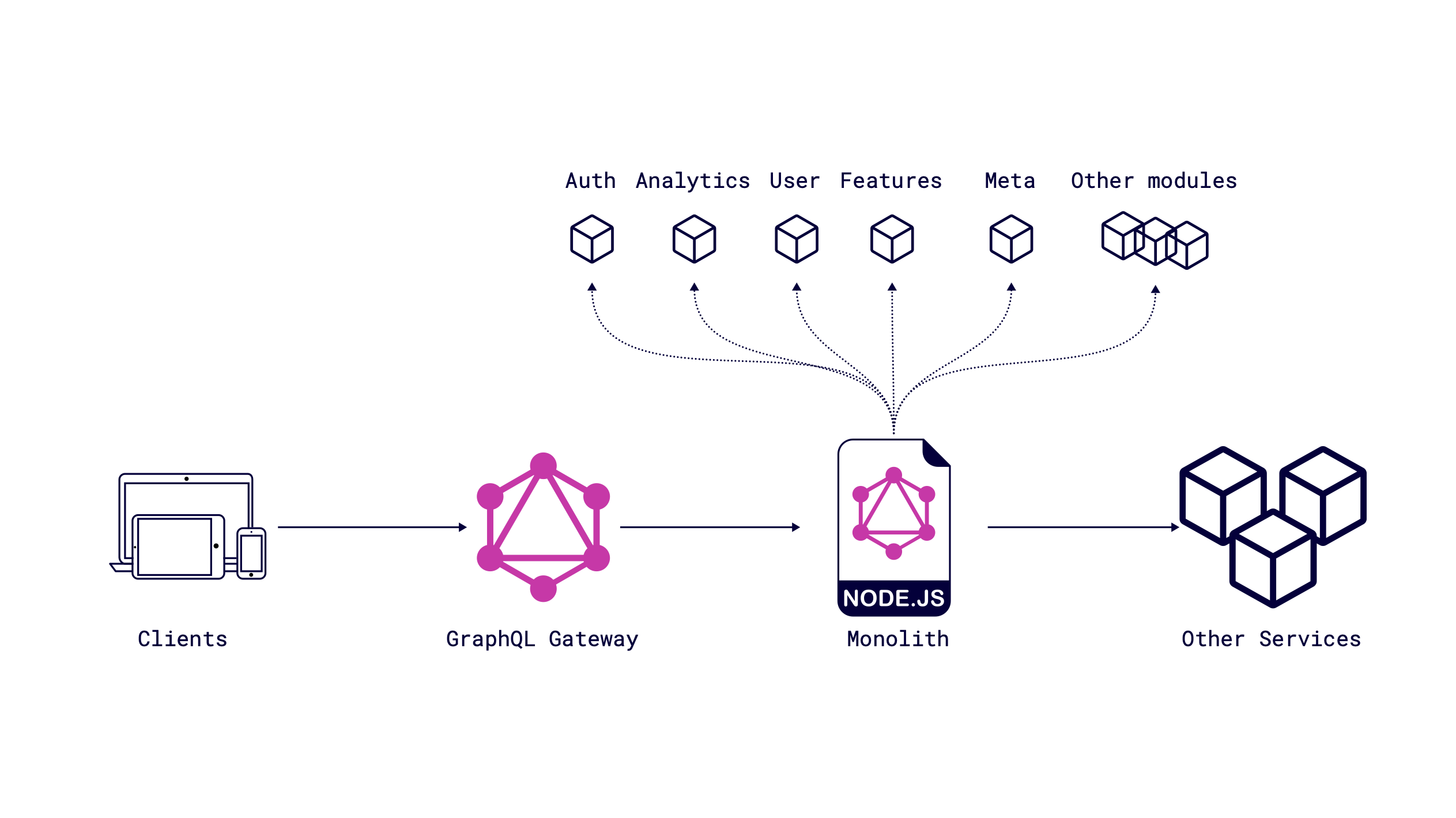
GraphQL Gateway is primarily responsible for serving GraphQL queries to consumers. It takes a query from a client, breaks it into smaller sub-queries, and executes that plan by proxying calls to the appropriate downstream subgraphs. When we started our journey, there was only Apollo Federation in the arena, and we used it. Still, now you can look at other options (e.g. Mercurius, Conductor, Hot Chocolate, Wundergraph, Hasura Remote Schemas ), compare benchmarks and decide what's important and preferable for your needs. The Gateway provides a unified API for consumers while giving backend engineers flexibility and service isolation.
Our Monolith is GraphQL Subgraph for now. As usual, it has the same characteristics as microservice, but from the perspective of our migration is still a monolith but with integrated GraphQL. This step is important to define GraphQL schema based on GraphQL principles and reduce the approach when we move the REST approach to the GraphQL world. If you're a newbie in GraphQL, I highly recommend these articles:
- Official GraphQL Specification. Thinking in Graphs
- Designing your first GraphQL Schema by Apollo team
II. Decompose monolith service to GraphQL Subgraphs
The decomposition of the monolith is a long process, it doesn't matter at which language service was written. From that perspective, think of this step as a long process which not directly connected with GraphQL, but we use the benefits of GraphQL to decompose it into microservices. We decomposed the first module of the monolith as a GraphQL subgraph and added it as a subgraph to the Federation schema:
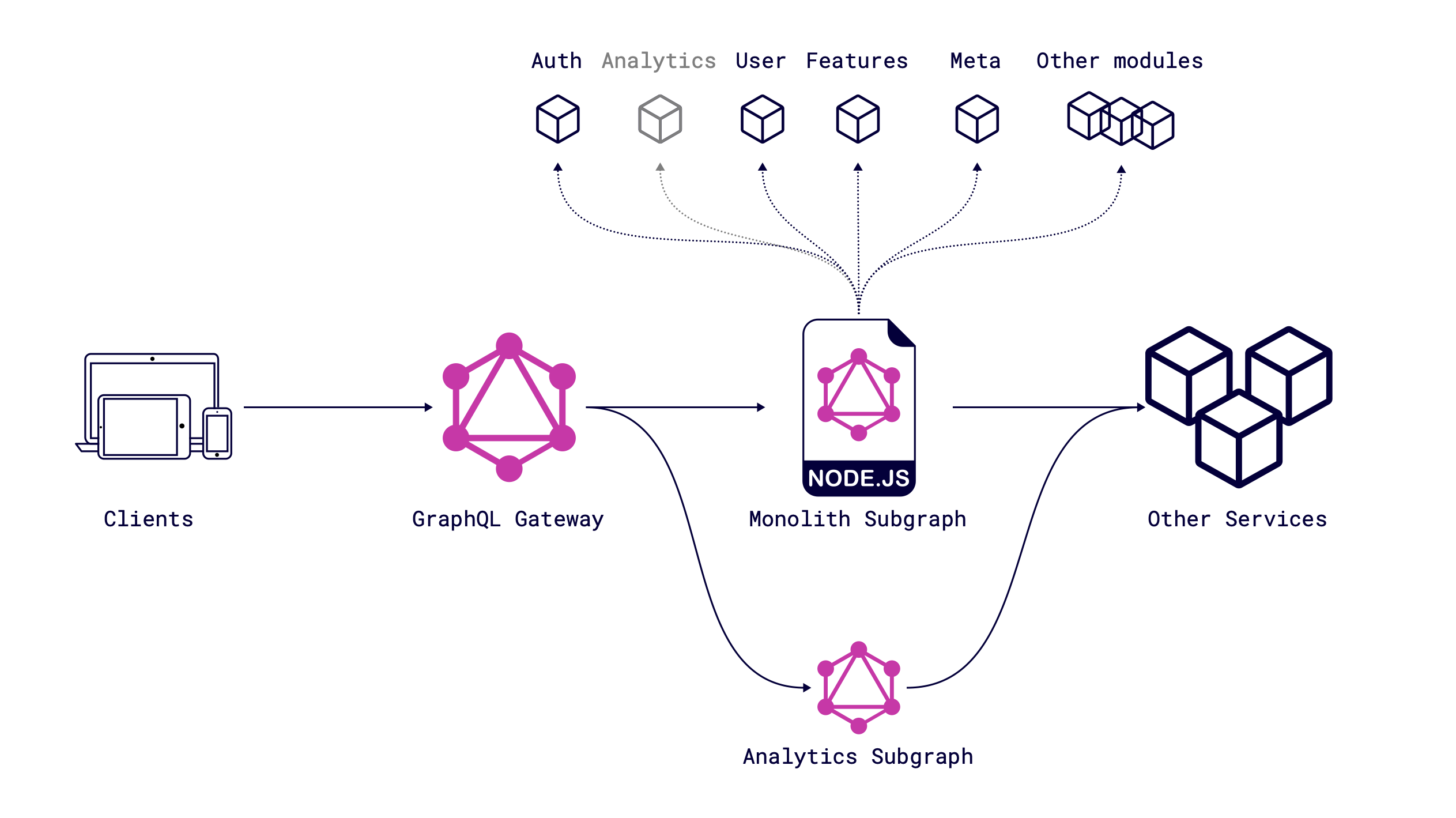
For now, Analytics is not a module of monolith service anymore. It works as a GraphQL subgraph and isolates all needed business logic within itself.
The GraphQL Federation by Apollo offers a way how to decompose GraphQL monolith to several subgraphs, but if you use Mercurius as I mentioned above or something else, you can use the same approach with opensource solutions, like GraphQL Tools by The Guild. In the current state, two existing subgraphs have identical resolvers for analytics, and we should mark one resolver as deprecated & second one as used. Technically, you just need to mark migrated GraphQL field with GraphQL directives in two places, as @shareable one in monolith to indicate that field will be received from another subgraph and @override in the new subgraph to indicate a new field.
# GraphQL Monolith
type Query {
analytics: [Analytics]
}
type Analytics @shareable {
id: ID!
}
# GraphQL Analytics Subgraph
extend type Query {
analytics: [Analytics]
}
type Analytics @override(from: "monolith") {
id: ID!
}
GraphQL Gateway processes it during schema composition and creates a single schema with correctness data sources, all analytics requests go to Analytics Subgraph and you can easily deprecate the legacy part of the monolith in favor of the new service.
If you need to migrate fields between subgraphs with slowly shift traffic to test new service before going to production for all clients, please read article by Reddit team, how they've migrated their schema between subgraphs with Blue/Green Subgraph deployment.
III. Mesh and introduce GraphQL to existing services
We have hundreds of services that were written in the latest 15 years, which means services were developed in different languages by different teams and have different states of support for now. A bunch of services requires one type of HTTP Headers, which should be provided, another bunch has different HTTP Headers and different API sources (e.g., REST, SOAP, RPC), and we need to get some data from them to calculate some business data within our particular infrastructure.
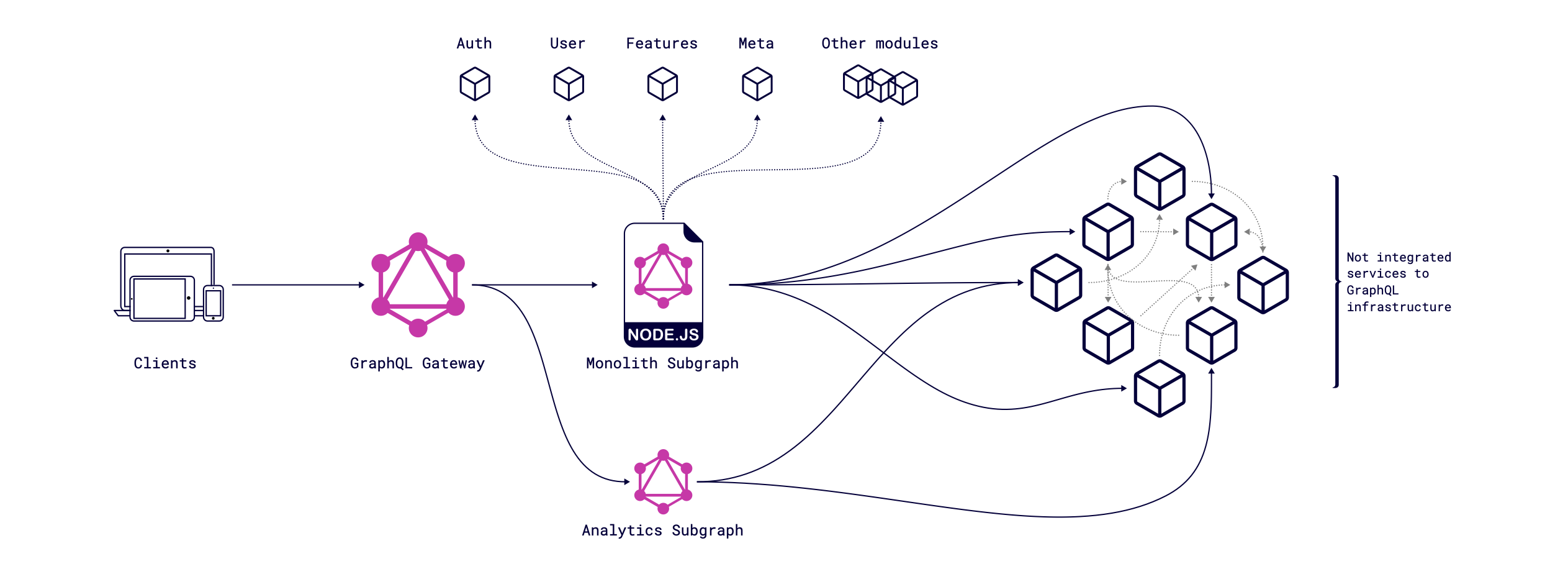
We have several ways to manage it and unify the process for GraphQL infrastructure.
Transport Service that consumes many API/Sources types
The transport service is a standalone service, a layer (API gateway) between existing services and our infrastructure.
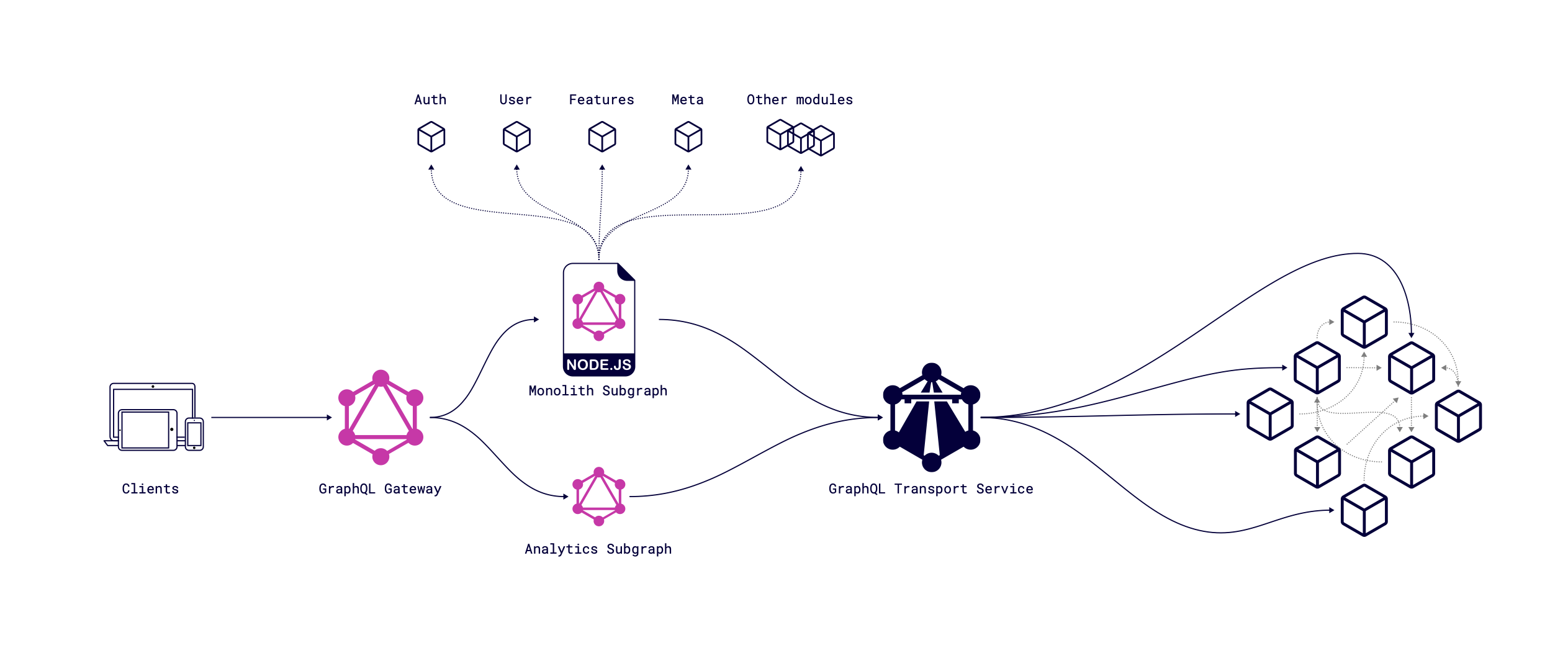
This approach is adding another layer within the infrastructure to process everything in one place. It has benefits:
- Expose GraphQL schema in one place for the whole of our infrastructure and don't mind about other services within GraphQL infrastructure.
- Progressively migrate existing non-GraphQL services under a unified GraphQL API.
- Use one caching strategy for the whole GraphQL infrastructure and easily maintain it.
- Unify the logic for other services in one place.
- It can be developed and maintained by a single team, which speeds up the process of migrating the monolith.
Great news, we have an open-source solution by The Guild GraphQL Mesh that covers many APIs and could be easily extended by writing needed plugins.
As usual, every approach has some cons & props. Let’s take a look at the cons:
- A transport service is a bottleneck of the system because it processes all requests from subgraphs in one place, and you should be careful because it multiplies the number of requests for complex GraphQL queries. So, you need a good single-core processor because NodeJS runs on a single thread, and be careful with performance. Of course, you should have vertical & horizontal auto-scaling to process traffic spikes.
- An extra layer in your infrastructure increased complexity. Better to decrease the complexity of the system (the best code is no code at all).
GraphQL as a part of existing services written on Java, Kotlin, .NET, etc.
More native way of integration GraphQL in existing services is to do it with adding GraphQL servers. GraphQL is language agnostic, so we don’t have a lock for using different languages. Let’s take Kotlin as an example, e.g. Kotlin GraphQL Server. As we integrate Messages Service as a subgraph, we don't need to go through GraphQL Transport Service (GTS) and can get all needed data directly from the source. The diagram below shows that Java & Kotlin services are integrated into the Federation schema as subgraphs and the system’s complexity is extremely low.
For our flexibility, we can combine both approaches; if we introduce a new service, we can easily get all the needed data from subgraphs, but if we need some existing data from not integrated services, we can use GTS as transport or add existing service as a subgraph.
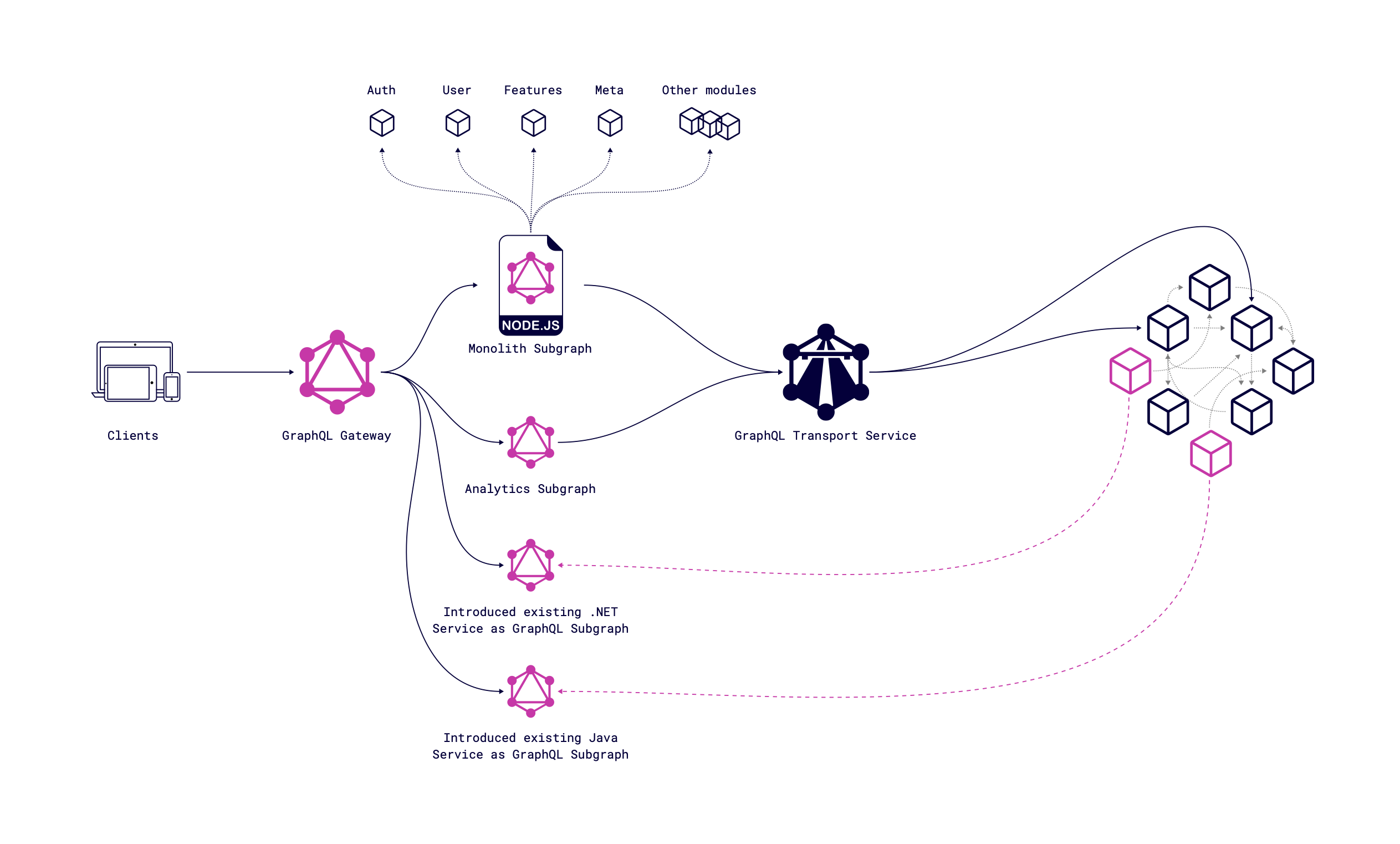
After migrating the monolith to microservices, we will still have a core service that may contain some data, or we can get rid of it completely.
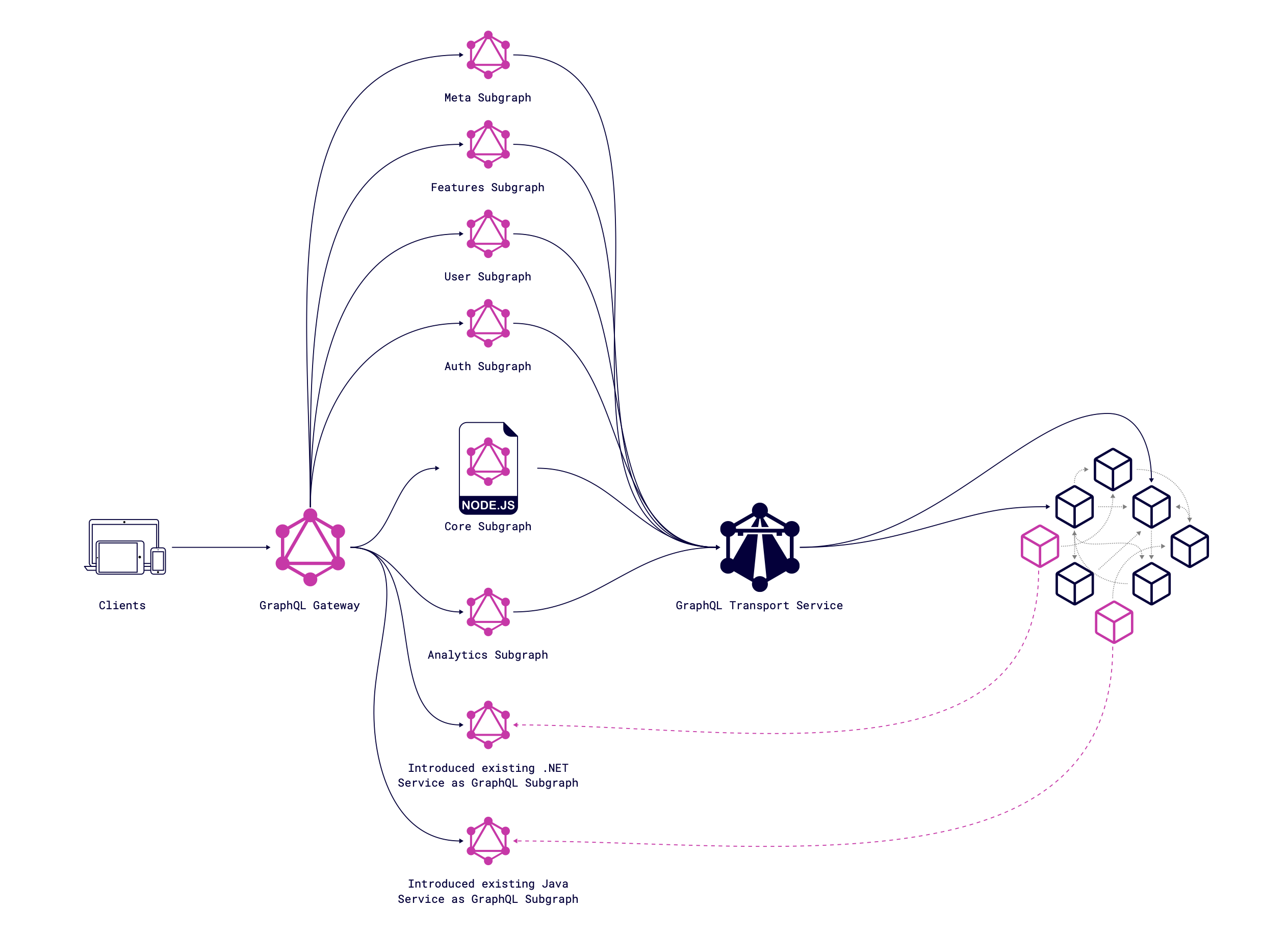
IV. Schema Registry
During development and especially in situations when several teams contribute to the GraphQL infrastructure, our schema is growing and changing. To support this healthy schema evolution, we are able to use the GraphQL Schema Registry.
The GraphQL Schema Registry is a persistent system element that retains all schemas and schema modifications for each subgraph. Its role encompasses validating individual DGS schemas and merged schemas, ensuring compliance. Lastly, the registry assembles the unified schema and supplies it to the gateway.
GraphQL Schema Registry serves the main purpose of preventing breaking changes. This empowers you to strategize in advance and implement any required schema modifications promptly.
In the first implementation, we used an approach without a Schema Registry, and we had a dynamic composition of schema during runtime. We had no way to validate changes and prevent breaking schema on production.
Integrated Schema Registry to our scope we can describe by next diagram:
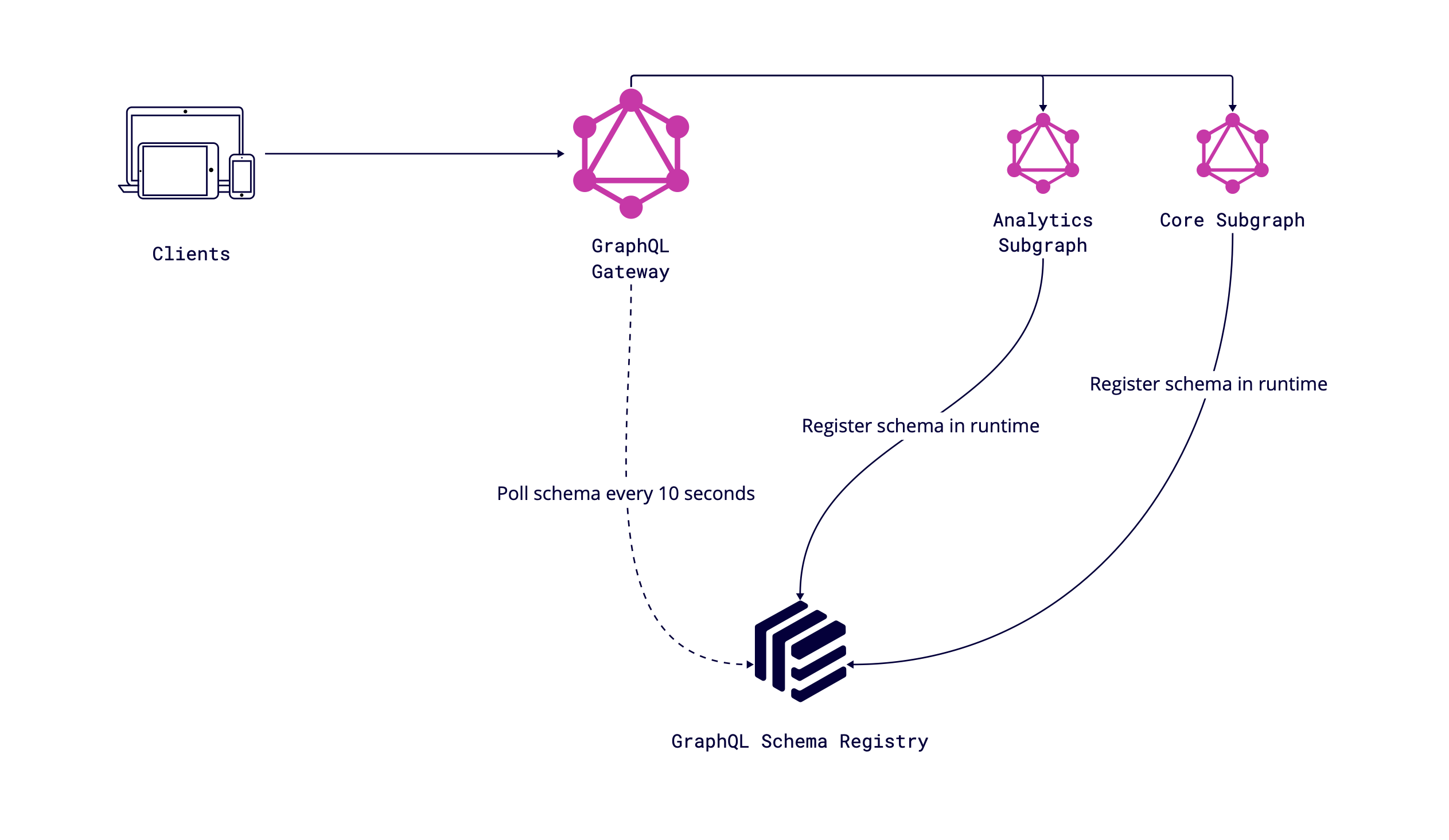
Every subgraph pushes schema in runtime to Schema Registry Service that processes it and validates it for breaking changes. Also, it exposes a unified schema, which is used by Gateway as a main schema of GraphQL infra.
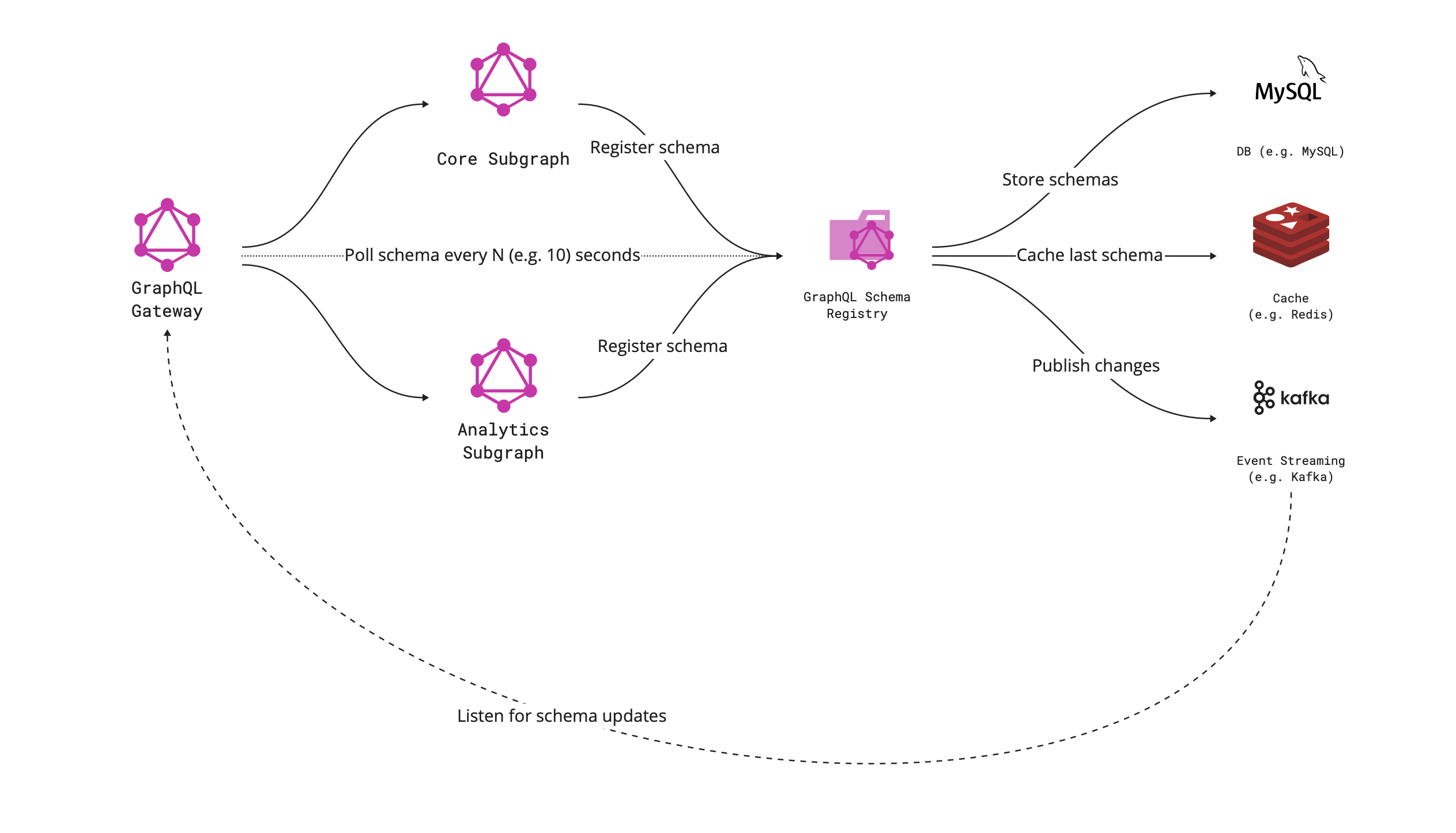
When Schema Registry Service gets a new schema of the updated subgraph, it starts processing the schema from the perspective of composition to the whole schema and checks the main directions:
- The updated schema is a valid GraphQL schema & could be executed.
- The updated schema composes seamlessly with the rest of the subgraph's schemas to create a valid composed schema for Gateway.
- The updated schema is backward compatible and clients shouldn't upgrade their codebase.
If all of the above conditions are met, then the schema is checked into the Schema Registry. The service store schema in Database and cache it in Redis. The next step is to publish changes through Kafka to Gateway, and we have updated the schema within the environment.
The good news is that we have several options not to create our custom solution from scratch and spend a lot of time on it:
- Completely open-sourced solution written with similar tools
- The open-sourced solution by The Guild that could be self-hosted
- The solution by Apollo, they deliver an utterly outsourced solution, which I don't really like because it has many limitations and questions from the perspective of GDPR and more.
V. Observability
Observability can be achieved with a set of tools that we combine to get the best possible way of detecting ongoing issues and preventing a bunch of them. We split the observability into three directions:
- Alerting - immediately notify when something goes wrong or a metric begins to form that leads to a problem
- Discovery - determine what exactly isn't working properly
- Finding - debug why something isn't working as expected
As I said at the begging of the article, I will not go into the implementation details. Alerting & discovery can be done similarly as for other services in your company, like with OpsGenie, Grafana, Graylog, and so on.
From the perspective of the realization of GraphQL infrastructure, the interesting direction is "Finding". How to find the problem? How to find the bottleneck of the system? Distributed Tracing System (DTS) will help answer this question. Distributed tracing is a method of observing requests as they propagate through distributed environments. In our scenario, we have dozens of subgraphs, gateway, and transport layer through which the request goes. We have several tools that can be used to detect the whole lifecycle of the request through the system, e.g. Jaeger, Zipkin or solutions that provided DTS as a part of the solution NewRelic.
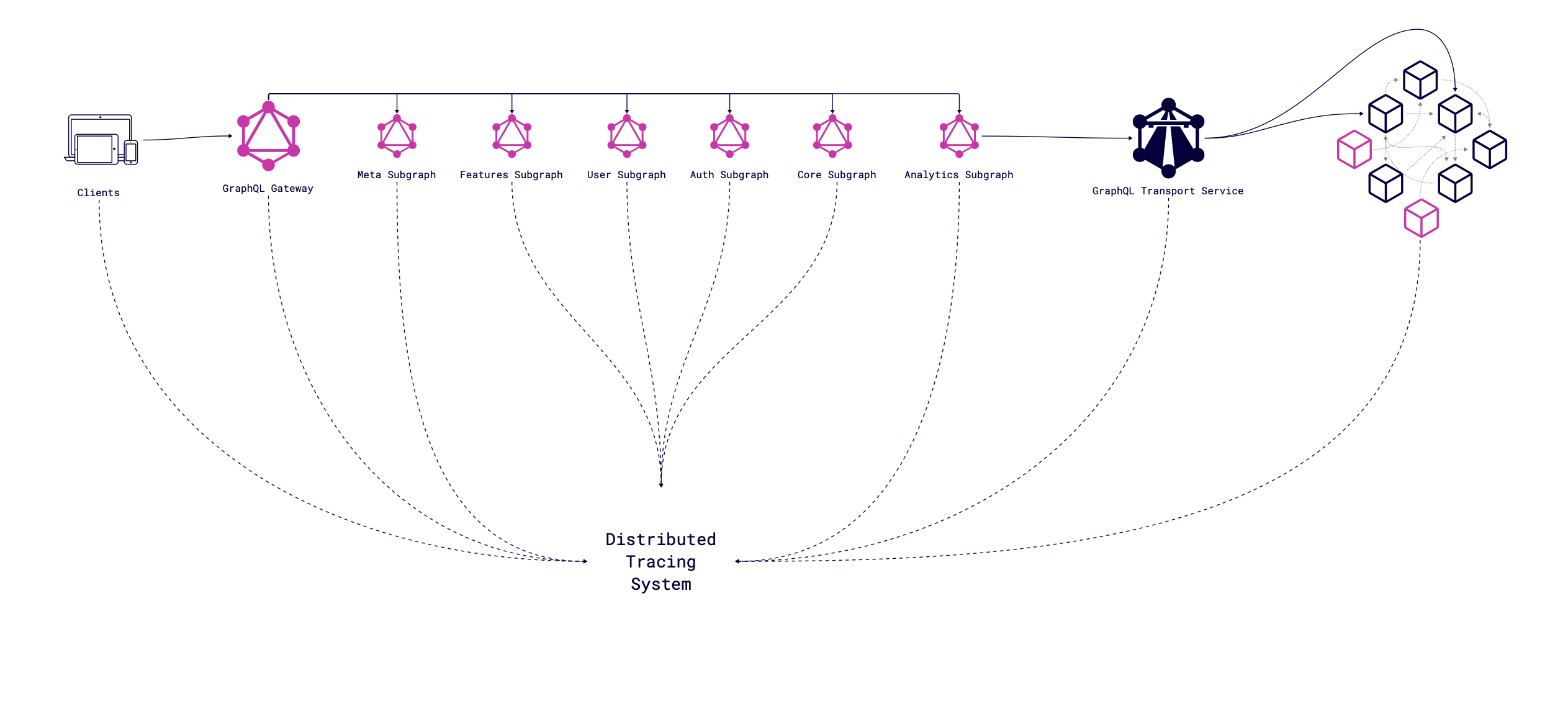
For example, let’s take a look at GitHub repository with integrated Open Telemetry to Apollo Federation.
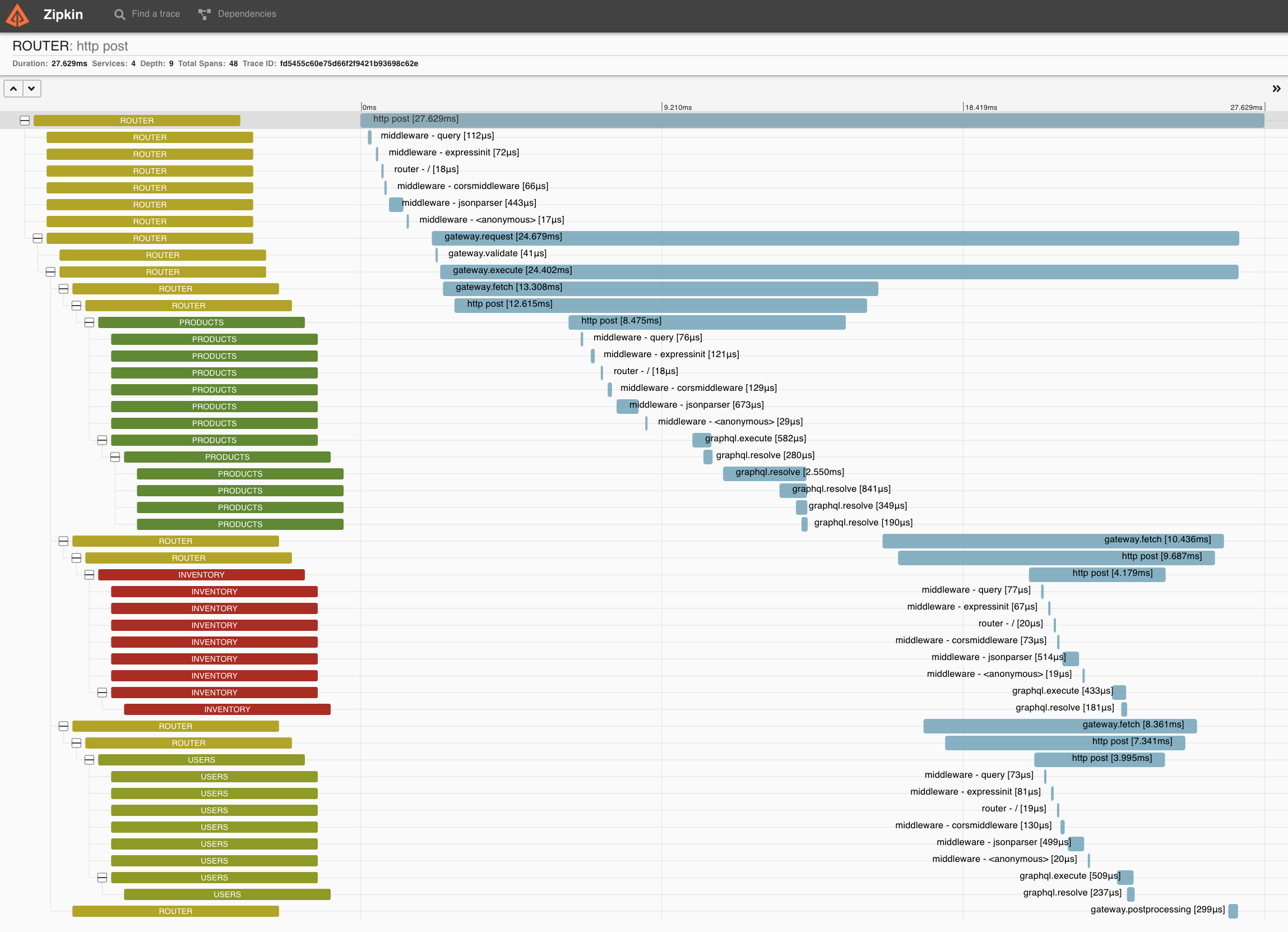
Based on the UI provided by DTS, we can easily find bottlenecks of the system and tune the system’s performance, that important one from the perspective of scaling infrastructure to the whole company.
Closing Thoughts
GraphQL Federation has lowered the connectivity of the monolith and works as a perfect solution for the different client (Web, Mobile) needs. The addition of GraphQL had fantastic feedback from product teams because they had a typed contract inside their TypeScript/Kotlin codebase and a beautiful playground where they can make an example of new functionality in a matter of minutes.
Despite our positive experience as a team, GraphQL Infrastructure migration requires high commitment from other teams and seamless cross-functional collaboration, as you remembered we had several approaches with unification HTTP headers and API protocols and integration GraphQL servers should be on the side of partner teams, not to overload the core team. It also requires some work as a developer advocate because explaining how to work/develop properly with GraphQL and what the best practices are is necessary. The trend of usage is increasing and this improves the situation:
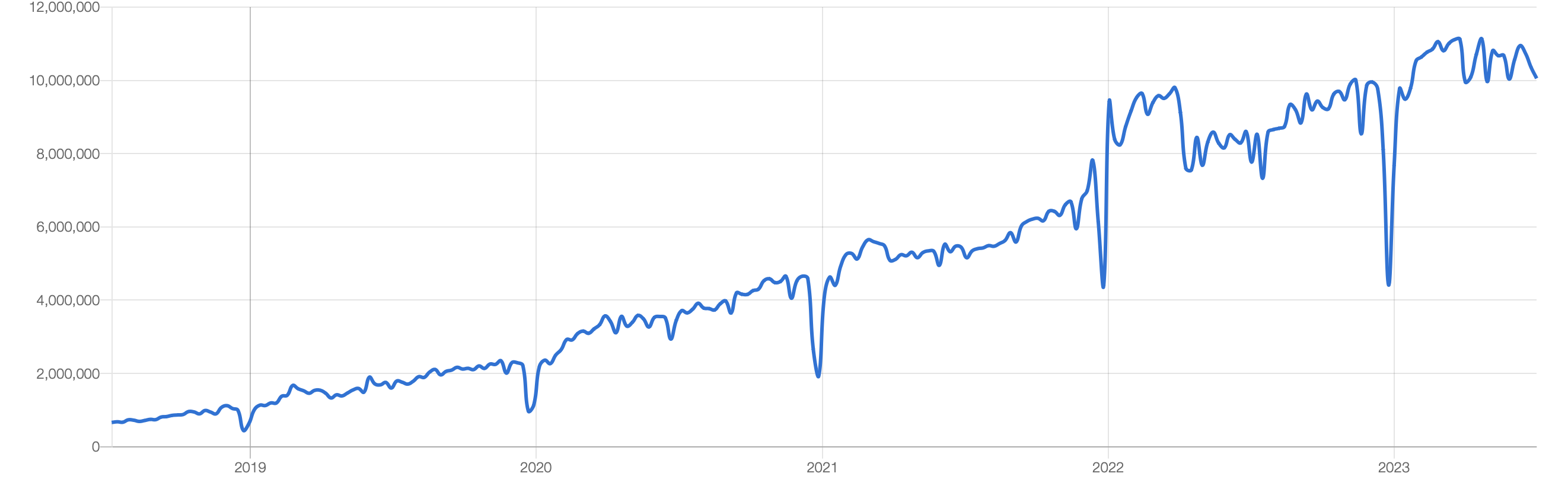
Technologies are constantly changing and our responsibility to choose aligned technologies for particular purpose. From my perspective and experience, GraphQL is good candidate for core infrastructure for customer-centric products.