- Published on
Resilience and fault tolerance of Web Oriented Services

Table of contents
Introduction
Microservice architecture have become the new model for building modern cloud-native applications as a part of distributed systems.
One of the key aspects of building modern web-oriented distributed systems is resilience and fault tolerance. Fault tolerance is the ability for a system to remain in operation even if some components used to build the system fail. With synchronous communication between microservices, it is important that the failure of one service doesn't cause other services to fail as well.
Otherwise, the unavailability of a single service can cause further microservice to fail until the entire system is no longer available.
| Availability | Downtime per year |
|---|---|
| 99% (2 nines) | 3 days 15 hours |
| 99.9% (3 nines) | 8 hours 45 minutes |
| 99.99% (4 nines) | 52 minutes |
| 99.999% (5 nines) | 5 minutes |
| 99.9999% (6 nines) | 31 seconds |
I would like to repeat definitions given by Adrian Hornsby from AWS Patterns for Resilient Architecture, AWS, 2019:
Resilience is:
- art of being able to run system with failures.
- ability for a system to handle and eventually recover from unexpected conditions.
Also, one more thing in terms of architecture is prevented cascading failures.
This article will cover only the questions of resilience and fault tolerance with high availability. The issues of monitoring, alerting, logging, CI/CD, health checks, etc. will not be considered in this article. Some examples will use TypeScript & NestJS.
Resilience methodologies
Before we start looking at ways how to solve the problems relevant with resilience and fault tolerance, let's understand how to index these issues. One of ways is Chaos Testing, you can find more details here, and this is brilliant article about Chaos Testing. Think about scenarios like below and find out how the system behaves:
- Service X isn't able to communicate with Service Y.
- DB isn't accessible.
- Service X isn't able to connect to the Service Y with HTTP, e.g. Service Y supports only HTTPS.
- Server is down or not responding.
- Inject timeouts into the tested services.
Identifying failure points in architecture
If you have been troubleshooting your services and individual service performance, you have already likely identified a few services that either receive or send a lot of requests.
Optimizing those requests is important and potentially could help you to prolong availability of whole system. But, given a high enough load, the services sending or receiving those requests are likely failure points for your application.
Load Balancing
Microservices have the benefit that each microservice can be scaled independently of the other microservices. For that it is needed that the call to a separated microservice can be distributed to several instance by a load balancer. Load balancing solutions allow an application to run on multiple network nodes, removing the concern about a single point of failure
The good approach for Load Balancing is HAPRoxy, which stands for High Availability Proxy, is a popular open source solution TCP/HTTP Load Balancer and proxying solution.
Load Balancing Algorithms
The load balancing algorithms that are used determines which server will be selected when load balancing. HAPRoxy offers several options for algorithms. In addition, to the load balancing algorithm, servers can be assigned a weight parameter to manipulate how frequently the server is selected, compared to other servers. In HAPRoxy Configuration Manual you can find all existing algorithms, I would like to use roundrobin (as a default one) for our purposes but if you have specific needs, please use your own algorithm.
Internal-Communication Load Balancing
The idea of internal load balancing can be implemented with a load balancer for each microservice. The load balancer must obtain the information about the currently available microservices from the service discovery:
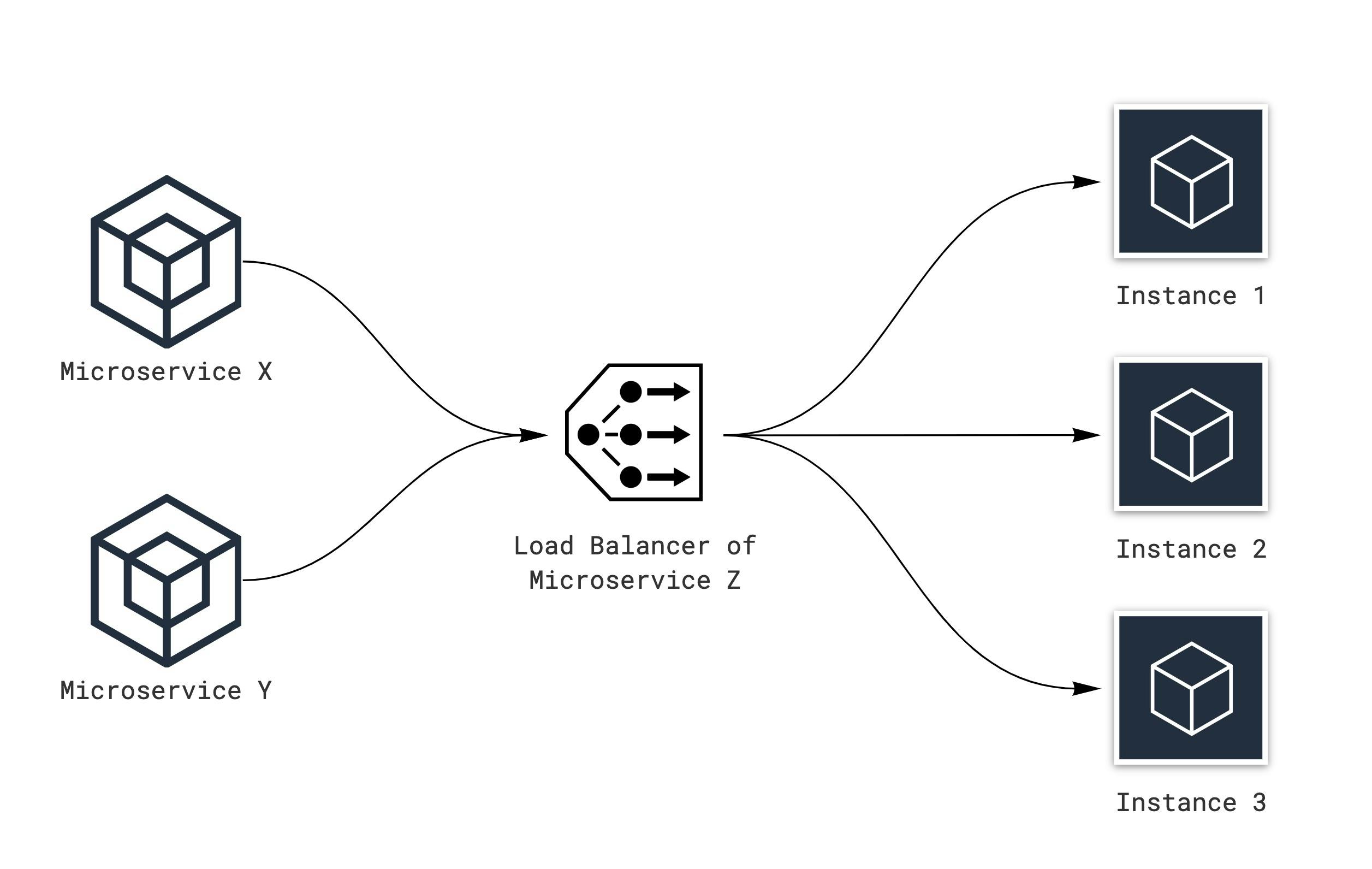
Decentralized load balancing is great idea, we could deploy our microservices canary and load balancer is single point of failure only for one microservice. The entire microservices' system should work without one microservice, important that the failure of one microservice doesn't cause other microservices to fail as well.
External Load Balancing with HAPRoxy
HAProxy is a very performant open source reverse proxy that works with both Layer 4 and Layer 7 protocols. It’s written in C and is designed to be stable and use minimal resources, offloading as much processing as possible to the kernel. Like JavaScript, HAProxy is event driven and single threaded.
We should provide multiple HAPRoxy instances per each our Data Center to be able that we don't have a failure point of this layer for high availability.
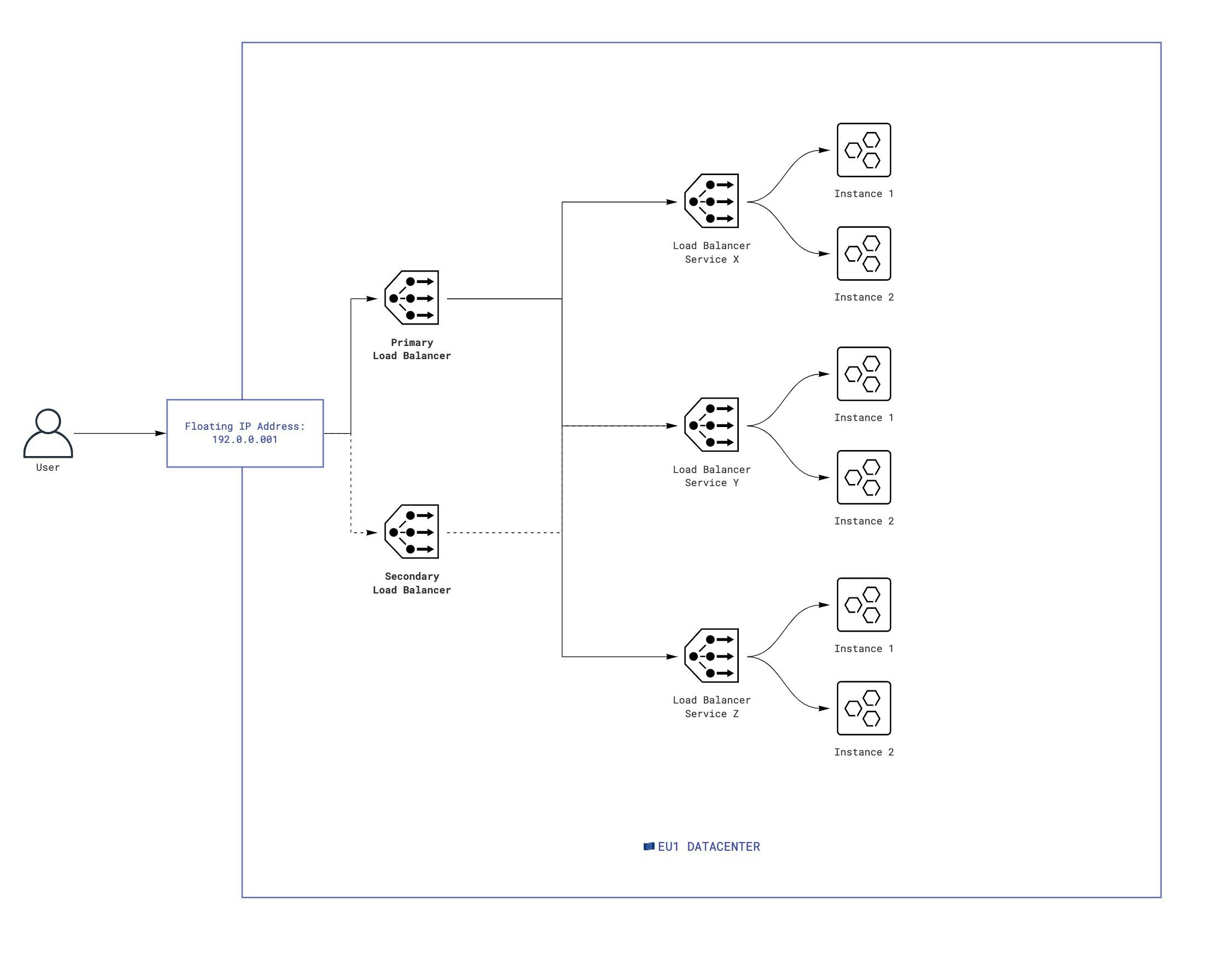
Floating IPs let you redirect all incoming network traffic between any of existing HAPRoxy within the same datacenter (EU1 in the scheme below). It can be resolved with Keepalived and Virtual Router Redundancy Protocol. As a result you can use floating IPs to create server infrastructures without single points of failure.
Health Check
HAProxy uses health checks to determine if a backend server is available to process requests. This avoids having to manually remove a server from the backend if it becomes unavailable. The default health check is to try to establish a TCP connection to the server i.e. it checks if the backend server is listening on the configured IP address and port.
If a server fails a health check, and therefore is unable to serve requests, it is automatically disabled in the backend i.e. traffic will not be forwarded to it until it becomes healthy again. If all servers in a backend fail, the service will become unavailable until at least one of those backend servers becomes healthy again.
For certain types of backends, like database servers in certain situations, the default health check is insufficient to determine whether a server is still healthy.
Cache
Caching is a great and simple technique that helps improve your app's performance and resilience. It acts as a temporary data store providing high performance data access. I would concentrate on three different strategies which could be combined are In-Memory Cache, External Cache (Redis, Memcached, etc.), No Cache strategy. But how cache help us increase fault tolerance and resilience? If the service X had a successful request to service Y, we cached the response in Redis. But then some problems happened in service Y, we get the same request for the data again, we can go to the cache and return the user the correct information from the cache. But it is important to remember the right caching strategy.
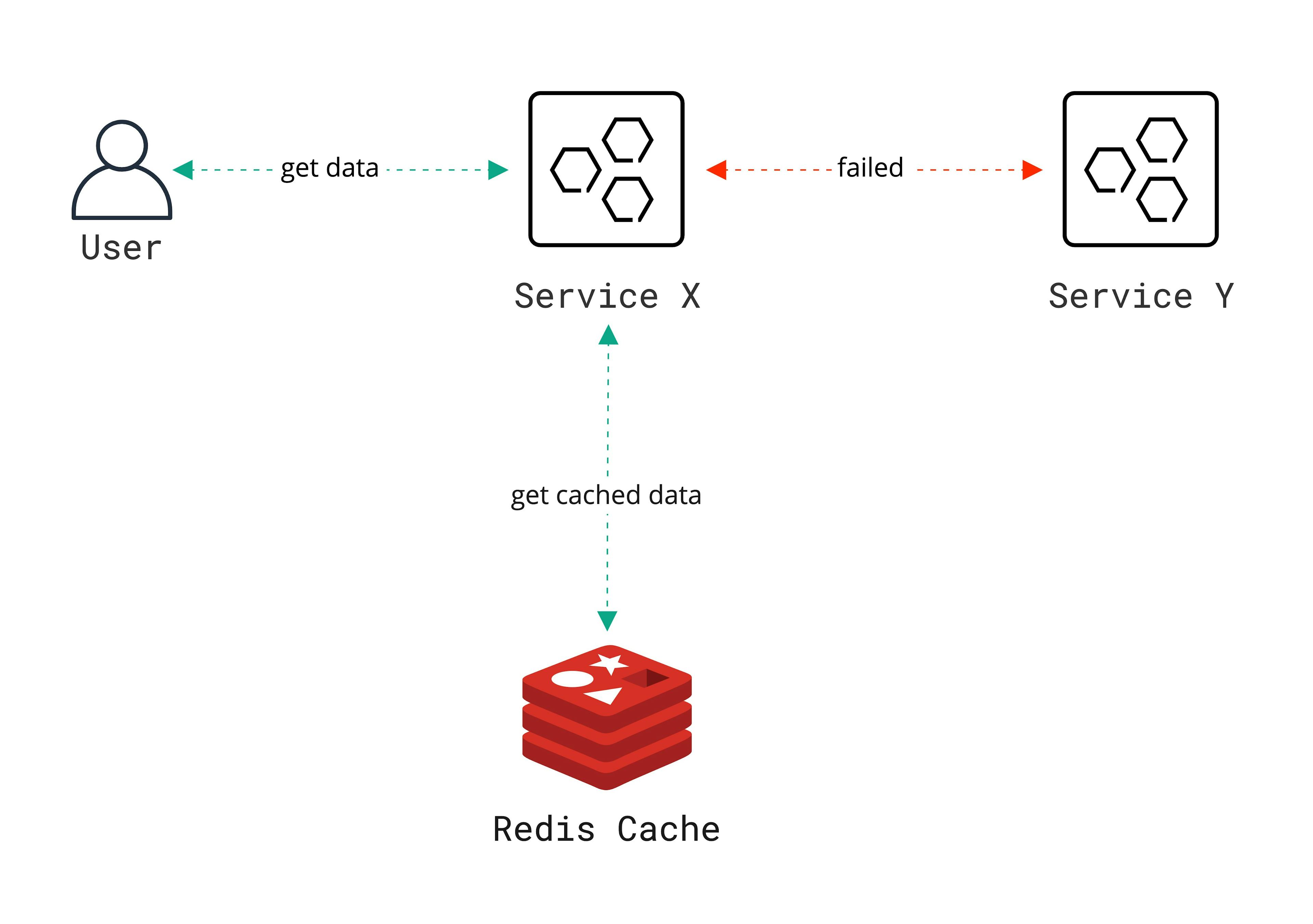
In-Memory Cache!!
The simplest cache is based on the In-Memory Cache. In-Memory Cache represents a cache stored in the memory of the web server.
This is the fastest one, but it has a strong disadvantage in terms of data compatibility. The cache is destroyed between crashed, re-deployments, deployments of services. One of potential cases for storing data in memory cache of the web server is store sensitive data. Because Redis was designed not for maximum security but for maximum performance and simplicity. That means, every engineer within trusted environment can read non-encrypted data in key-value store.
Redis is designed to be accessed by trusted clients inside trusted environments. This means that usually it is not a good idea to expose the Redis instance directly to the internet or, in general, to an environment where untrusted clients can directly access the Redis TCP port or UNIX socket.
The simplest implementation of In-Memory Cache based on the interface:
interface CacheClientInterface {
get<T>(key: string): Promise<T | null>;
put<T>(key: string, value: T, time: number): Promise<T>;
delete<T>(key: string): Promise<void>;
}
I would like to use memory-cache package as a quick solution. An example of using combined with default lifecycle events from NestJS, onModuleInit and onApplicationShutdown help us initialize in-memory cache when application is started and clear in-memory cache when application is off.
import inMemoryCache from 'memory-cache';
interface CacheClientInterface {
get<T>(key: string): Promise<T | null>;
put<T>(key: string, value: T, time: number): Promise<T>;
delete<T>(key: string): Promise<void>;
}
class InMemoryCacheClient implements CacheClientInterface {
private inMemoryCache;
constructor() {}
async onModuleInit() {
this.inMemoryCache = new inMemoryCache.Cache();
}
onApplicationShutdown() {
this.inMemoryCache?.clear();
}
async get<T>(key: string): Promise<T> {
return this.inMemoryCache.get(key);
}
async put<T>(key: string, val: T, time: number): Promise<T> {
this.inMemoryCache.put(key, val, time);
}
async delete(key: string): Promise<void> {
this.inMemoryCache.del(key);
}
}
External Cache
It's slower than an in-memory cache but should be faster than hitting the source of truth. It also prevents the cache from being wiped out between crashes and deployments, or when 3rd party service has issues for some reasons, and we can prevent starting cascading failures. We have several opensource options of noSQL key-value in-memory data storage systems, e.g. Redis, Memcached. I would like to use Redis (but if you need more details of comparing these two opensource solutions, please read Redis or MemCached). Also, we should implement CacheClientInterface from the example below. I will consider a third-party cache using Redis as an example:
- Redis can be accessed by all the processes of your applications, possibly running on several nodes (something local memory cannot achieve).
- Redis memory storage is quite efficient, and done in a separate process.
- Redis can persist the data on disk if needed.
- Redis can replicate its activity with a master/slave mechanism in order to implement high-availability.
No cache
In this approach, an application talks directly with external services.
Let's start with external cache, we have several options:
- Redis
- ElasticSearch Cache
Redis is a powerful service exposing several useful data structures while providing many commands to interact with them. But Redis has a limitation: the data stored in a Redis instance must fit completely in memory. For this reason, Redis is best used only as a cache, not as a data source.
Where the rest of the problem is and how to solve it we are going to explore in Part 2 of our series.